
李飞飞团队为主的研究人员发表了一篇论文,仅用不到 50 美元,用时26分钟就训练出了一个人工智能 “推理” 模型s1。以下是论文的主要内容:
一、引言
近年来,语言模型(LMs)的性能提升主要依赖于训练时计算资源的增加,通过大规模的自监督预训练来实现。这些强大的模型为新的扩展范式奠定了基础,即测试时扩展(test-time scaling)。这一方法旨在通过在测试阶段增加计算资源来获得更好的结果。OpenAI的o1模型展示了这一范式的潜力,但其具体方法尚未公开,导致许多研究者尝试复制其模型。本文旨在寻找一种最简单的方法来实现测试时扩展和强大的推理性能。
我们首先策划了一个包含1,000个问题的小型数据集s1K,这些问题配有推理轨迹,基于三个标准:难度、多样性和质量。其次,我们开发了预算强制(budget forcing)方法,通过在测试阶段控制模型的思考时间来实现计算资源的管理。具体来说,当模型生成的思考标记超过预设限制时,我们强制结束其思考过程;或者,当模型试图结束思考时,我们通过添加“Wait”来延长其思考时间,以促使模型进行更深入的推理。通过在s1K 上对Qwen2.532B-Instruct模型进行监督微调(SFT),并结合预算强制方法,我们的模型s1-32B在竞赛数学问题上超越了OpenAI的o1-preview 模型,最高提升达27%(MATH和AIME24)。此外,通过预算强制方法扩展s1-32B的性能,使其在AIME24上的表现从50%提升至57%。我们的模型、数据和代码已开源,详见https://github.com/simplescaling/s1。
二、推理数据策划以创建s1K
2.1 初始收集59K样本
我们从16个不同的来源收集了59,029个问题,遵循三个指导原则:质量、难度和多样性。质量方面,我们确保数据集的高质量,忽略格式不佳的数据集。难度方面,我们选择具有挑战性且需要显著推理努力的问题。多样性方面,我们从不同领域收集数据集,以覆盖不同的推理任务。我们收集的数据集包括:
NuminaMATH:包含30,660个来自在线网站的数学问题。
AIME:1983-2021年的美国数学邀请赛(AIME)问题。
OlympicArena:包含4,250个来自各种奥林匹克竞赛的天文学、生物学、化学、计算机科学、地理学、数学和物理学问题。
OmniMath:包含4,238个竞赛级别的数学问题。
AGIEval:包含2,385个来自标准化测试(如SAT和LSAT)的英语、法律和逻辑问题。
s1-prob:包含182个来自斯坦福大学统计学博士资格考试的概率问题。
s1-teasers:包含23个来自量化交易面试的高难度脑筋急转弯问题。
对于每个问题,我们使用Google Gemini Flash Thinking API 生成推理轨迹和答案,得到59K个问题、推理轨迹和答案的三元组。
2.2 最终选择1K样本
为了从59K个问题中筛选出1K个样本,我们经过三个阶段的过滤:
质量过滤:去除包含API错误的样本,检查格式错误的样本,最终保留 51,581个样本。
难度过滤:使用两个指标评估难度:模型性能和推理轨迹长度。我们评估了Qwen2.5-7B-Instruct 和Qwen2.5-32B-Instruct 两个模型在每个问题上的表现,最终保留24,496个样本。
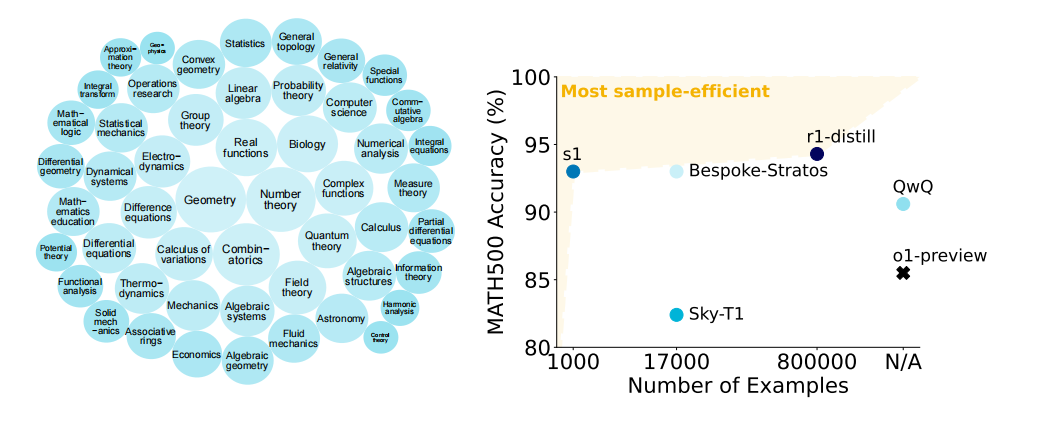
多样性过滤:使用Claude 3.5 Sonnet根据数学主题分类系统(MSC)对每个问题进行分类,最终随机选择1,000个样本,覆盖50个不同的领域。
三、测试时扩展
3.1 方法
我们将测试时扩展方法分为两类:顺序扩展和并行扩展。顺序扩展方法中,后续计算依赖于之前的计算结果,例如长推理轨迹。并行扩展方法中,计算独立进行,例如多数投票。
我们提出了一种简单的解码时干预方法,称为预算强制(budget forcing),通过在测试阶段强制执行最大和/或最小思考标记数来实现。具体来说,我们通过添加结束思考标记分隔符和“Final Answer:”来提前结束思考阶段,使模型提供当前最佳答案。为了强制执行最小思考标记数,我们抑制结束思考标记分隔符的生成,并可选地在模型当前推理轨迹中添加“Wait”字符串,以鼓励模型进一步探索。
3.2 评估指标
我们建立了三个评估指标来衡量不同方法的测试时扩展效果:
控制(Control):衡量方法对测试时计算资源的可控性。
扩展(Scaling):衡量方法的平均斜率,即性能随计算资源增加的提升速度。
性能(Performance):衡量方法在基准测试中的最高性能。
四、结果
4.1 设置
我们使用Qwen2.5-32B-Instruct模型在s1K上进行监督微调,得到我们的模型s1-32B。微调过程使用基本的超参数设置,训练时间为26分钟,使用16个NVIDIA H100 GPU。
评估方面,我们选择了三个具有代表性的推理基准测试:AIME24、MATH500和GPQA Diamond。我们使用“lm-evaluation-harness”框架进行评估。
4.2 性能
我们使用Qwen2.5-32B-Instruct模型在s1K数据集上进行监督微调,并结合预算强制方法进行测试时扩展。主要结果如下:
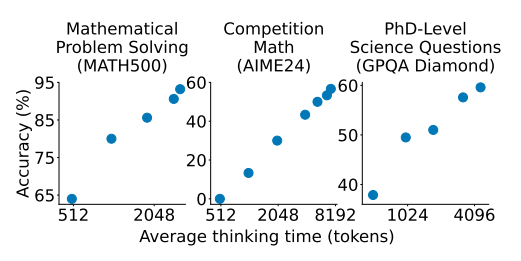
性能提升:在AIME24、MATH500和GPQA Diamond等基准测试中,s1-32B模型的表现显著优于基线模型Qwen2.5-32B-Instruct。例如,在AIME24测试中,s1-32B的准确率从50%提升到57%。
样本效率:s1-32B模型仅使用了1000个样本进行微调,但其性能已经接近或超过了许多使用更大规模数据集训练的模型。
扩展能力:通过预算强制方法,模型在测试时的性能随着推理时间的增加而提升,表现出良好的扩展能力。
五、消融实验
5.1 数据数量、多样性和难度
我们测试了仅使用质量(1K-random)、仅使用多样性(1K-diverse)和仅使用难度(1K-longest)的数据集对模型性能的影响。结果表明,仅使用质量、多样性和难度中的任何一个标准都会导致性能显著下降。这强调了结合这三个标准的重要性。
5.2 测试时扩展方法
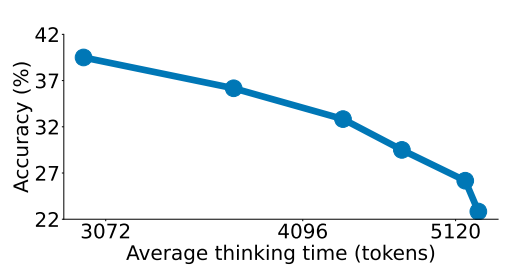
我们比较了预算强制方法与其他测试时扩展方法,包括条件长度控制方法(TCC/SCC/CCC)和拒绝采样(RS)。结果表明,预算强制方法在控制、扩展和性能方面均优于其他方法。
六、讨论与相关工作
6.1 样本高效推理
我们的研究显示,通过在预训练模型上进行少量样本的监督微调,可以激活模型的推理能力,并通过测试时扩展进一步提升性能。这与LIMA中的“表面对齐假设”一致,即少量样本可以对齐模型以满足用户偏好。
6.2 测试时扩展
我们区分了顺序和并行测试时扩展方法。顺序扩展方法通过后续计算依赖于之前的计算结果来实现,而并行扩展方法通过独立生成多个解决方案并选择最佳结果来实现。我们的研究表明,顺序扩展方法在推理任务中更为有效。
七、结论
我们的工作展示了通过简单的监督微调和测试时扩展方法,可以显著提升语言模型的推理性能。我们开源了我们的模型、数据和代码,以促进未来在简单推理方向上的研究。未来的工作可以探索更复杂的测试时扩展方法,以及将强化学习应用于推理模型的可能性。
来源:AI道上
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章




暂无评论...